What is DNS and which is best DNS for Pakistan?
In this article, we will explore what is “DNS”.
DNS stands for “Domain Name System”. You can think of it as a phone book on the Internet. We human beings access information on the web using domain names, such as google.com or duckduckgo.com. Web browsers (Chrome/Firefox/Safari, etc.) interact through IP addresses. DNS converts domain names to numerical IP addresses so that browsers can load the web page(s) from the web server. This process could be referred to as “DNS resolution.”
Each device (which could be your computer, mobile, tab, etc.) connected to the Internet has its unique IP address, and using that other machine, find that specific device. DNS servers come to the rescue and help humans by saving them from memorizing the IP addresses such as 1.2.3.4 (in IPv4 format) or more complex newer alphanumeric IP addresses such as 2410:ab00:2058:1::a239:e8a2 (in IPv6 format).
Selecting the best DNS for Pakistan hinges on reliability, speed, and security. Cloudflare’s 1.1.1.1 is a favored choice, offering swift resolution times and privacy features. Google’s Public DNS is another solid option, prioritizing speed and security. Ultimately, the best DNS for Pakistan depends on individual needs and internet usage patterns.
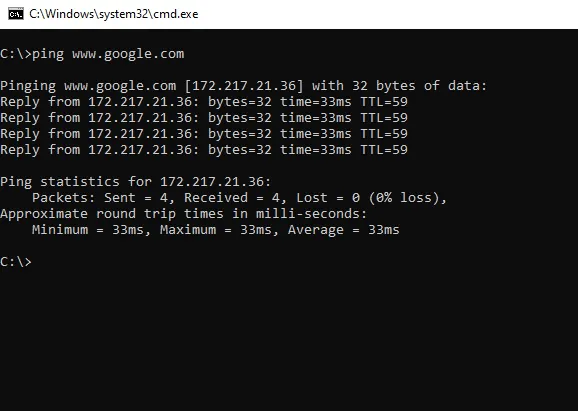
search google ip using ping command
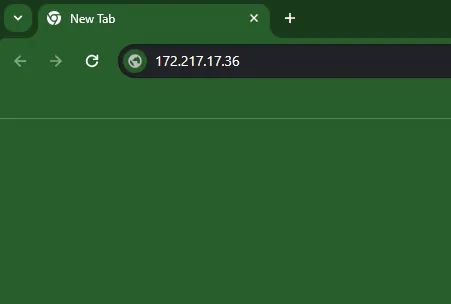
using ip to browse google page
How does DNS Work?
DNS works ‘behind the scenes,’ and one does not need to worry about much. But without it, your Chrome or any other browser wouldn’t know where to put your web page request, and finding the required information will be a headache.
The flow of the process of converting domain names into machine addresses (which is the work of a DNS server) constitutes converting domain names into a computer-friendly form (an IP address), and as aforementioned, each address is unique and belongs to a certain device connected to the Internet – like a street address is used to find a particular home.
When a visitor desires to visit a website, a conversion must occur between what that visitor types into his web browser (google.com) and the devices’ address(es) in a computer-friendly form necessary to locate the google.com website. So, for the web browser, the DNS lookup occurs in the background and requires no other input from the visitor’s computer but just the initial request.
DNS Components
There are four main components or servers that play a part in the DNS (or during the ‘conversion’ process). We can assume the DNS query as if a librarian is being asked to find a book and gradually narrowing down their search:
1) The Recursor (a type of DNS server):
Usually, this is the first stop your lookup request makes. It gets the first request, checks its recent cached addresses, and then sends a command to other servers further down the pipeline if it can’t find the IP for your website from its cache. Consider it: the books just returned to the librarian, who did not replace them in their respective racks.
2) Root servers:
They are the servers that help in converting domain names into IP addresses by redirecting the DNS requests to specific servers belonging to an alphabet. There are 13 root nameservers, starting from ‘a’ to ‘m’, like a.root-servers.net, b.root-servers.net, and so on.
Consider this a specific section in a library, for example, book sections for science, technology, arts, etc.
3) TLD (top-level-domain) nameserver:
They further shorten the path for a DNS request to directly hit the TLD server for the domain whose website you would like to visit. For example, for visiting google.com, these servers will direct the request to the server hosting .com TLDs data.
There is more than one server for each TLD globally to speed up the process and for redundancy purposes.
Consider it as a rack of books in the science section of a library.
4) The authoritative nameserver:
This is the final stop (or “dead-end”) for your lookup request. Generally, these are the servers commonly identifiable as “nameservers” for the server(s) of a hosting company. Such servers are authorized to ‘serve’ the client’s (a device or a computer or a phone) incoming DNS requests specific to a domain. The data they keep are known as “resource records,” and the place where they keep them is a text file known as a “DNS zone.” The existence of a domain on such a server is referred to as “DNS-hosted” for that domain.
The resource records consist of data which are IP addresses of the (hosting) server (known as “A” records), text (“TXT”) records for verification and authentication purposes, mail exchanger (“MX”) records for specifying the mail server for that domain. Other record types are CNAME, SRV, AAAA (IPv6 “A” records), and NS (nameservers hostnames), to name a few.
Consider this as the required book you asked the librarian to check for you on library shelves – for example, an Astronomy book by some specific author (so how this was located: Library > Books > Section > Astronomy > Author > the required book).
DNS Resolution Stages/Steps
- A user loads their browser and fills in the domain name whose website he/she likes to visit. This domain translation query is first received by a recursor (or ‘resolver’ at an ISP) unless specified on the device itself (known as “local resolvers”).
- That resolver then seeks the help of a root server.
- The root server then identifies the domain’s TLD and refers the request to the server(s) holding the data of that TLD. For example, for browsing, https://www.host24.com.pk, the root server will send the request to .com.pk TLD server(s) only.
- The TLD server then responds with the glue records of the nameservers of that domain.
- Lastly, the recursive resolver sends a request to the domain’s nameservers (NS) holding its DNS zone data.
- The IP address for the domain is returned from the nameservers, which are pointing to an IP address of a server (usually, a web server).
- The DNS resolver then responds to the web browser with the IP address of the domain requested in the first step.
Once the browser gets the IP address of the domain, it is then able to request the web page:
- The browser makes an HTTP request to the IP address of the (web) server.
- The server at that IP returns the web page to be rendered in the user’s browser.
About DNS Caching and its need
DNS caching involves keeping DNS data closer to the requesting client so that the DNS request(s) can be resolved efficiently – without generating additional queries down the DNS lookup path. Hence improving loading times and, as a result, reducing bandwidth/CPU usage. DNS (zone) data can be cached in different types of locations, each of which will keep DNS records for a specified amount of time as per the TTL (time-to-live) set in the DNS zone of the domain.
There are two types:
1) Browser-based Caching:
By default, new variants of web browsers are designed to cache DNS records for a specified amount of time. Hence, the nearer the DNS caching occurs to the browser, the fewer steps must be taken to search the cache and make the exact requests for looking at an IP address. Browser cache is the first place where the DNS records are checked.
In your Chrome browser, you can see the status of your DNS cache by pointing to chrome://net-internals/#dns.
2) OS-level Caching:
The OS-level DNS resolver (or local resolver) is the second and last stop before a DNS request leaves your device. A process in your OS is commonly known as a “stub resolver” or DNS client. When an application sends a request to the resolver, it first searches its DNS cache to see if it has the same record.
If this cannot be located, it sends a DNS request (with a recursive flag set) outside the LAN to a DNS recursive resolver at your Internet service provider (ISP) premises.
When the recursive resolver inside your ISP receives a DNS request, it will also check to see if the requested domain-to-IP-address translation is already stored inside its local database, like all previous steps.
There are additional functionalities built into the recursive resolver depending on the types of records it caches:
If the resolver only has NS records for the authoritative nameservers, it will query those name servers directly, bypassing several steps in the DNS request chain.
This acts as a ‘shortcut,’ and it prevents lookups from the root and TLD nameservers (in our case, .com TLD) and speeds up the resolution of the DNS query.
>> But, If the resolver does not have the NS records, it will send a query to the TLD servers directly (.com TLD, in our case), bypassing the root nameserver.
>>> However, if, unfortunately, the resolver does not have records pointing to the TLD nameservers, it will then seek the root servers. If the DNS cache has been purged, only then this event will take place.